标准差公式
差的意思是离正常有多远
标准差
标准差是数值分散的测量。
你可能想先去阅读 这个比较简单的标准差网页。
在这里我们会解释标准差的公式。
标准差的符号是 σ(希腊语字母 西格马,英语 sigma)。
这是标准差的公式:
![[ (1/N) 乘 (xi - mu)^2 从 i=1 到 N 的总和] 的平方根](images/standard-deviation-formula.gif)
开玩笑!用人语来讲可以吗?
好的。逐步来。
假设我们有一些数值,像:9、2、5、4、12、7、8、11。
计算这些数值的标准差:
公式已经包括了这四步,下面我再具体解释。
公式说明
我们会用一些数值作为例子:

例子:森森有 20棵蔷薇丛。
每棵丛上花的数目是
9、2、5、4、12、7、8、11、9、3、7、4、12、5、4、10、9、6、9、4
求标准差。
一、求数值的平均
在上面的公式 μ(希腊语字母 "缪",英语 "mu")是全部数值的平均……
例子:9、2、5、4、12、7、8、11、9、3、7、4、12、5、4、10、9、6、9、4
平均是:
9+2+5+4+12+7+8+11+9+3+7+4+12+5+4+10+9+6+9+4 20
= 140 20 = 7
所以:
μ = 7
二、从每一个数值减去平均,然后求差的平方
这是公式的这个部分:
![]()
xi 是什么意思?它们是个别的 x值:9、2、5、4、12, 7、……
例如, x1 = 9, x2 = 2, x3 = 5 等等
就是说: "从每一个数值减去平均,然后求差的平方",像这样
例子(续):
(9 - 7)2 = (2)2 = 4
(2 - 7)2 = (-5)2 = 25
(5 - 7)2 = (-2)2 = 4
(4 - 7)2 = (-3)2 = 9
(12 - 7)2 = (5)2 = 25
(7 - 7)2 = (0)2 = 0
(8 - 7)2 = (1)2 = 1
…… 等等 ……
结果是::
4、25、4、9、25、0、1、16、4、16、0、9、25、4、9、9、4、1、4、9
三、求结果的平均。
求平均:把所有的值加起来,然后除以值的个数。
先把上一步算出来的值加起来。
我们怎样用数学的语文来说:"加起来"?我们用 "西格马": Σ
这个简单的总和符号的意思是把项相加:

总和符号
我们想从 1 到 N 把数值加起来,N=20,因为有 20个数值:
例子(续):
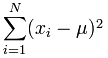
这个的意思是:从 (x1-7)2 到 (xN-7)2,把所有的数值加起来
在上一步我们已经计算了 (x1-7)2=4 等,所以我们只需把结果加起来:
= 4+25+4+9+25+0+1+16+4+16+0+9+25+4+9+9+4+1+4+9 = 178
这还不是平均值,我们要除以个数,就是乘以 "1/N":
例子(续):
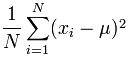
平方差的平均 = (1/20) × 178 = 8.9
(注意:这叫 "方差")
四、取平方根:
例子(终):
![[ (1/N) 乘 (xi - mu)^2 从 i=1 到 N 的总和] 的平方根](../data/images/standard-deviation-formula.gif)
σ = √(8.9) = 2.983……
大功告成!
样本标准差
慢着,还有一点……
……有时我们的数据只是总体的一个样本。
例子:森森有 20棵蔷薇丛,但她只数了 6棵上的花!
"总体" 是全部 20棵蔷薇丛,
而 "样本" 是森森数的 6棵。
假设森森的数据是:
9、2、5、4、12、7
我们可以估计标准差的值。
但当我们用样本作为总体的估计,标准差的公式变成这样:
样本标准差公式:
![[ (1/(N-1)) 乘 (xi - xbar)^2 从 i=1 到 N 的总和]的平方根](images/standard-deviation-sample.gif)
重要的改变是 除以 "N-1",而不除以 "N"(这叫 "贝塞尔无偏估计校正系数")。
我们也改变了符号,以显示数据是样本而不是总体:
- 平均变成 x (代表样本平均),而不是 μ(总体平均),
- 答案是 s(样本标准差),而不是 σ。
但算法是一样的,不过用 N-1 而不用 N。
我们来计算样本标准差:
一、求数值的 平均
例 2:用样本值 9、2、5、4、12、7
平均是 (9+2+5+4+12+7) / 6 = 39/6 = 6.5
所以:
x = 6.5
二、从每一个数值减去平均,然后求差的平方
例 2(续):
(9 - 6.5)2 = (2.5)2 = 6.25
(2 - 6.5)2 = (-4.5)2 = 20.25
(5 - 6.5)2 = (-1.5)2 = 2.25
(4 - 6.5)2 = (-2.5)2 = 6.25
(12 - 6.5)2 = (5.5)2 = 30.25
(7 - 6.5)2 = (0.5)2 = 0.25
三、求结果的平均。
求平均,把所有的数值加起来,然后除以数值的个数。
慢着……我们是在计算样本标准差,所以我们不除以个数 (N),而除以 N-1
例 2(续):
和 = 6.25 + 20.25 + 2.25 + 6.25 + 30.25 + 0.25 = 65.5
除以 N-1: (1/5) × 65.5 = 13.1
(这叫 "样本方差")
四、取平方根:
例 2(续):
s = √(13.1) = 3.619……
好了!
比较
用总体来计算,结果是:平均 = 7,标准差 = 2.983……
用样本,结果是:样本平均 = 6.5,样本标准差 = 3.619……
样本平均的误差是 7%,样本标准差的误差是 21%.
为什么要用样本?
主要是因为比较容易和便宜。
想象你想知道所有国民的想法……你不可能问上亿的人,所以你只问 1,000个人。
有句名言(相传是英国文人塞缪尔·约翰逊讲的):
"你不需要吃掉整条牛来知道它的肉是韧的。"
这就是取样本的精髓。我们不需要看总体来知道它的资料(例如平均和标准差),我们只需要看样本。
可是,当我们取样本时,精确度便会降低。
总结
总体标准差: |
|
|
| 样本标准差: | |