从分组频数
求平均、中位数和众数
![]()
用三个例子来说明
赛跑与顽皮小狗
我们从原始数据开始(还没分组的)……

大山测量了 21个赛跑者的时间(到最近的秒):
59、65、61、62、53、55、60、 70、64、56、58、58、62、62、68、65、56、 59、68、61、67
求 平均值,大山把所有的数加起来,然后除以数的个数:
| 平均 = | 59+65+61+62+53+55+60+70+64+56+58+58+62+62+68+65+56+59+68+61+67 |
| 21 | |
| = | 61.38095... |
求 中位数,大山把数顺序排列,然后找在正中间的数。

中位数是第 11个数:
53, 55, 56, 56, 58, 58, 59, 59, 60, 61, 61, 62, 62, 62, 64, 65, 65, 67, 68, 68, 70
中位数 = 61
求 众数,大山把数顺序排列,然后计算每一个数出现的次数。众数是出现最多的数(可以有多于一个众数):
53、55、56、56、58、58、59、59、60、61、61、62、62、62、64、65、65、67、68、68、70
62 出现了三次,比其他的数多,所以 众数 = 62
分组频数表
接下来,大山做了一个 分组频数表:
| 秒 | 频数 |
|---|---|
| 51 - 55 | 2 |
| 56 - 60 | 7 |
| 61 - 65 | 8 |
| 66 - 70 | 4 |
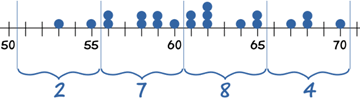
2个赛跑者的时间是在 51 和 55秒之间,7个的时间实在 56 和 60秒之间……
糟了!
刹时间原来的数据全部都没有了(顽皮的小狗!) |
……我们可以帮大山从分组频数表去求平均、中位数和众数吗?
答案是……不能。至少不能求精确的值。不过,我们可以求近似值。
哟个分组数据求平均值
剩下的数据只有:
| 秒 | 频数 |
|---|---|
| 51 - 55 | 2 |
| 56 - 60 | 7 |
| 61 - 65 | 8 |
| 66 - 70 | 4 |
- 这些组 (51-55、56-60等)的宽度(也叫组距)是 5
- 中点是在每个组距的正中:53、58、63 和 68
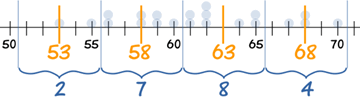
我们可以用中点来估计平均。
怎样做?
在 56 - 60 组里的 7个赛跑者的时间是在 56 和 60秒之间:
- 可能七个都跑了 56秒,
- 可能七个都跑了 60秒,
- 但更可能的是他们的时间都不一样,有些的时间是 56秒,有些是 57秒等等
所以我们就取个平衡,假设七个赛跑者的时间都是 58秒。
我们用中点来做个表:
| 中点 | 频数 |
|---|---|
| 53 | 2 |
| 58 | 7 |
| 63 | 8 |
| 68 | 4 |
我们的假设是:"2个人跑了 53秒、7个人跑了 58秒、8个人跑了 63秒、3个人跑了 68秒"。换句话说,我们想象数据是这样的:
53、53、58、58、58、58、58、58、58、63、63、63、63、63、63、63、63、68、68、68、68
然后我们把全部的数加起来,再除以 21(总共有 21个数)。最快的做法是把每个中点乘以相对的频数:
| 中点t x |
频数 f |
中点 × 频数 fx |
|---|---|---|
| 53 | 2 | 106 |
| 58 | 7 | 406 |
| 63 | 8 | 504 |
| 68 | 4 | 272 |
| 总计: | 21 | 1288 |
平均赛跑时间的近似值是:
| 平均近似值 = | 1288 | = 61.333…… |
| 21 |
与用原始数据求得的精确答案很接近。
从分组数据求中位数
我们再看看数据:
| 秒 | 频数 |
|---|---|
| 51 - 55 | 2 |
| 56 - 60 | 7 |
| 61 - 65 | 8 |
| 66 - 70 | 4 |
中位数是在正中的数,在这里是第 11个数,在 61 - 65 的组里:
我们可以说:"中位组是 61 - 65"
但如果我们想估计一个中位数,我们要仔细看看 61 - 65 的组。
组是叫 "61 - 65",但其实它可以从 60.5 到(但不包括) 65.5。
为什么?因为数据是测量到整数的秒数,所以如果真正时间是 60.5,这点便会被测量为 61。同样,65.4 会被测量为 65.
在 60.5 有 9个赛跑者,在下一个界限 65.5 有 17个赛跑者。在中间画一条直线,我们便可以看到 n/2 个赛跑者的中位数是:
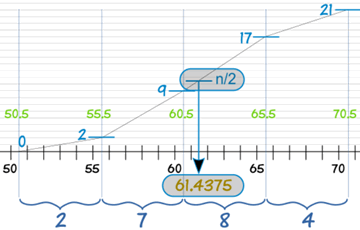
可以用这个简单公式来计算:
| 中位数近似值 = L + | (n/2) − B | × w |
| G |
其中:
- L 是包含中位数的组的下限
- n 是数据的个数
- B 是中位组前面所有组的累积频数
- G 是中位组的频数
- w 是组距
在这个例子里:
- L = 60.5
- n = 21
- B = 2 + 7 = 9
- G = 8
- w = 5
| 中位数近似值 | = 60.5 + (21/2) − 9 8 × 5 |
| = 60.5 + 0.9375 | |
| = 61.4375 |
用分组数据求众数
再来看数据:
| 秒 | 频数 |
|---|---|
| 51 - 55 | 2 |
| 56 - 60 | 7 |
| 61 - 65 | 8 |
| 66 - 70 | 4 |
密集群组(最大频数的组)是 61 - 65
我们说:"密集群组是 61 - 65"
但真正的众数可能根本不在这个组里!也可能有多于一个众数。没有原始数据我们不会知道。
可是,我们可以用这个公式来估计众数:
| 众数近似值 = L + | fm − fm-1 | × w |
| (fm − fm-1) + (fm − fm+1) |
其中:
- L 是密集群组的下限
- fm-1 是密集群组之前一个组的频数
- fm 是密集群组的频数
- fm+1 是密集群组之后一个组的频数
- w 是组距
在这个例子里:
- L = 60.5
- fm-1 = 7
- fm = 8
- fm+1 = 4
- w = 5
| 众数近似值 | = 60.5 + | 8 − 7 | × 5 |
| (8 − 7) + (8 − 4) | |||
| = 60.5 + (1/5) × 5 | |||
| = 61.5 | |||
最后的结果是:
- 平均近似值:61.333...
- 中位数近似值:61.4375
- 众数近似值:61.5
(你可以把这些值与上面用原始数据求得的平均、中位数和众数 61.38……、61 和 62 比较一下。)
这就是用分组数据去求平均、中位数和众数的近似值的做法。
我们现再来看两个例子,也多做一些练习!
小胡萝卜例子

例子:你在特种泥土里种了五十个小胡萝卜。你把它们挖出来,量度长度(到最近的 mm), 然后把结果分组:
| 长度(mm) | 频数 |
|---|---|
| 150 - 154 | 5 |
| 155 - 159 | 2 |
| 160 - 164 | 6 |
| 165 - 169 | 8 |
| 170 - 174 | 9 |
| 175 - 179 | 11 |
| 180 - 184 | 6 |
| 185 - 189 | 3 |
平均
| 长度(mm) | 中点 x |
频数 f |
fx |
|---|---|---|---|
| 150 - 154 | 152 | 5 | 760 |
| 155 - 159 | 157 | 2 | 314 |
| 160 - 164 | 162 | 6 | 972 |
| 165 - 169 | 167 | 8 | 1336 |
| 170 - 174 | 172 | 9 | 1548 |
| 175 - 179 | 177 | 11 | 1947 |
| 180 - 184 | 182 | 6 | 1092 |
| 185 - 189 | 187 | 3 | 561 |
| 总计: | 50 | 8530 |
| 平均近似值 = | 8530 | = 170.6 mm |
| 50 |
中位数
中位数是第 25 和 26个长度的平均,所以是在 170 - 174 的组里:
- L = 169.5 (170 - 174 组的下限)
- n = 50
- B = 5 + 2 + 6 + 8 = 21
- G = 9
- w = 5
| 中位数近似值 | = 169.5 + | (50/2) − 21 | × 5 |
| 9 | |||
| = 169.5 + 2.22…… | |||
| = 171.7 mm(到一个小数位) | |||
众数
密集群组是最大频数的组,就是 175 - 179 的组:
- L = 174.5 (175 - 179 组的下限)
- fm-1 = 9
- fm = 11
- fm+1 = 6
- w = 5
| 众数近似值 | = 174.5 + | 11 − 9 | × 5 |
| (11 − 9) + (11 − 6) | |||
| = 174.5 + 1.42... | |||
| = 175.9 mm(到一个小数位) | |||
年龄例子
年龄是个特别的频数。
如果我们说:"莎莎是 17岁",在她 18岁生日前,她一直都是 17岁。
她的年纪可能已经是 17年 364天,但我们仍然叫她 "17岁"。
因为这样,中点和组距都会有点改变。

例子:在一个热带岛屿上的 112个人的年龄分成以下的组别:
| 年龄 | 人数 |
|---|---|
| 0 - 9 | 20 |
| 10 - 19 | 21 |
| 20 - 29 | 23 |
| 30 - 39 | 16 |
| 40 - 49 | 11 |
| 50 - 59 | 10 |
| 60 - 69 | 7 |
| 70 - 79 | 3 |
| 80 - 89 | 1 |
在 0 - 9 组里的小孩可能已经差不多 10岁,所以这个组的中点是 5,而 不是 4.5
中点是 5、15、25、35、45、55、65、75 和 85
同样,在求中位数和众数时,我们也会以组距为 0、10、20 等等
平均
| Age | 中点 x |
人数r f |
fx |
|---|---|---|---|
| 0 - 9 | 5 | 20 | 100 |
| 10 - 19 | 15 | 21 | 315 |
| 20 - 29 | 25 | 23 | 575 |
| 30 - 39 | 35 | 16 | 560 |
| 40 - 49 | 45 | 11 | 495 |
| 50 - 59 | 55 | 10 | 550 |
| 60 - 69 | 65 | 7 | 455 |
| 70 - 79 | 75 | 3 | 225 |
| 80 - 89 | 85 | 1 | 85 |
| 总计: | 112 | 3360 |
| 平均近似值 = | 3360 | = 30 |
| 112 |
中位数
中位数是第 56 和 57个组的人的平均年龄,所以是在 20 - 29 的组里:
- L = 20 (包含中位数的组的下限)
- n = 112
- B = 20 + 21 = 41
- G = 23
- w = 10
| 中位数近似值 | = 20 + | (112/2) − 41 | × 10 |
| 23 | |||
| = 20 + 6.52…… | |||
| = 26.5(到一个小数位) | |||
众数
密集群组是最大频数的组,就是 20 - 29 的组:
- L = 20 (密集群组的下限)
- fm-1 = 21
- fm = 23
- fm+1 = 16
- w = 10
| 众数近似值 | = 20 + | 23 − 21 | × 10 |
| (23 − 21) + (23 − 16) | |||
| = 20 + 2.22…… | |||
| = 22.2(到一个小数位) | |||
总结
如果只有分组数据,我们不能求精确的平均值、中位数和众数,我们只能求 近似值。
求平均的近似值,我们用组距的中点。
| 中位数近似值 = L + | (n/2) − B | × w |
| G |
其中:
- L 是包含中位数的组的下限
- n 是数据的个数
- B 是中位组前面所有的组的累积频数
- G 是中位组的频数
- w 是组距
| 众数近似值 = L + | fm − fm-1 | × w |
| (fm − fm-1) + (fm − fm+1) |
其中:
- L 是密集群组的下限
- fm-1 是密集群组之前一个组的频数
- fm i是密集群组的频数
- fm+1 是密集群组之后一个组的频数
- w 是组距